Vor fast 20 Jahren haben wir den Blog mit WordPress (Open Source) gestartet – ohne Webebanner oder versteckter Werbung. Das ist auch heute noch so.
Von Anfang an haben wir Wert auf Qualität der Beiträge gelegt, indem wir beispielsweise Originaltexte mit Quellen angegeben, und dadurch von unserer Meinung abgegrenzt haben.
In der Zwischenzeit werden wir alle von KI generierten Inhalten überschwemmt. Da ist es aus unserer Sicht gut, mehr auf Qualität, als auf Quantität zu setzen. Ganz im Sinne von unserer Marke:
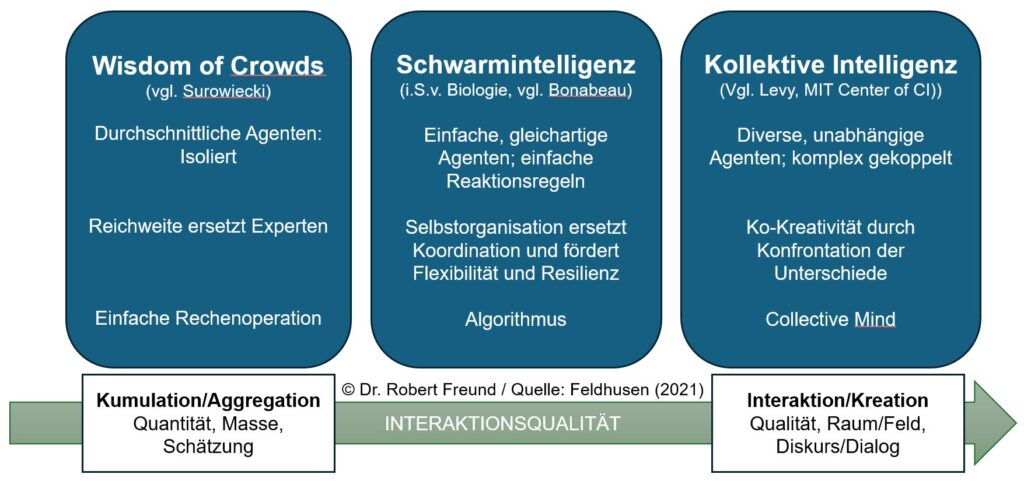
In dem Blogbeitrag Wisdom of Crowds – Schwarm Intelligenz – Kollektive Intelligenz bin ich schon einmal intensiver auf die Unterscheidung der jeweiligen Ansätze eingegangen. Darin zitiere ich Feldhusen (2021), der sich wiederum auf Lévy vom MIT Center of Collective Intelligence bezieht. Es lohnt sich, dessen Auffassung noch etwas genauer zu betrachten:
„Die Netzwerkgesellschaft wird nicht von einer Expertenintelligenz getragen, die für andere denkt, sondern von einer kollektiven Intelligenz, die die Mittel erhalten hat, sich auszudrücken. Der Anthropologe des Cyberspace, Pierre Lévy, hat sie untersucht: »Was ist kollektive Intelligenz? Es ist eine Intelligenz, die überall verteilt ist, sich ununterbrochen ihren Wert schafft, in Echtzeit koordiniert wird und Kompetenzen effektiv mobilisieren kann. Dazu kommt ein wesentlicher Aspekt: Grundlage und Ziel der kollektiven Intelligenz ist gegenseitige Anerkennung und Bereicherung …« (Lévy, 1997, S. 29). Um allen Missverständnissen zuvor zu kommen, richtet er sich ausdrücklich gegen einen Kollektivismus nach dem Bild des Ameisenstaates. Vielmehr geht es ihm um eine Mikrovernetzung des Subjektiven. »Es geht um den aktiven Ausdruck von Singularitäten, um die systematische Förderung von Kreativität und Kompetenz, um die Verwandlung von Unterschiedlichkeit in Gemeinschaftsfähigkeit« (ebd., S. 66)“ (zitiert in Grassmuck 2004).
L ÉVY, PIERRE (1997): Die Kollektive Intelligenz. Eine Anthropologie des Cyberspace, Bollmann Verlag, Mannheim.
In der Grafik ist zu erkennen, dass es bei Kollektiver Intelligenz auch um diverse, unabhängige Agenten geht, die komplex gekoppelt sind. Aus der heutigen Perspektive können damit auch KI-Agenten im Netzwerk diverser Akteure gemeint sein. Auch in so einem Netzwerk würde es also nicht DIE Expertenintelligenz geben. Intelligenz (menschliche, künstliche, hybride Formen) würde sich also im Netzwerk verteilt, immer wieder neu bilden.
Um das zu erreichen, müssen allerdings Voraussetzungen erfüllt sein, die von den Tech-Konzernen mit ihren KI-Agenten manchmal „vergessen“ werden. Grundlage und Ziel der Kollektiven Intelligenz sind nach Lévy „gegenseitige Anerkennung und Bereicherung“. Bei diesen Punkten habe ich bei den proprietären KI-Modellen so meine Zweifel.
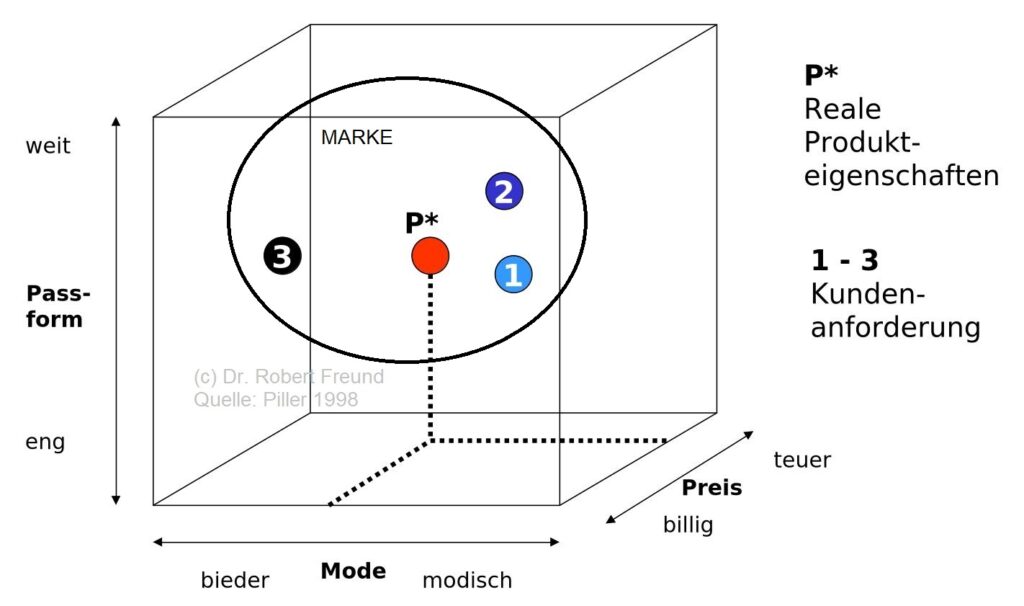
Es hat den Anschein, dass es sich die Modeindustrie leisten kann, die Anforderungen ihrer Kunden zu ignorieren. Die Abbildung zeigt, eine heute immer noch anzutreffende Diskrepanz zwischen den Kundenanforderungen und den realen Produkteigenschaften.
Schauen wir uns die drei Dimensionen Passform (eng-weit), Mode (bieder-modisch) und Preis (billig-teuer) an, so sind zunächst die Kundenanforderungen 1, 2 und 3 positioniert. Es wird deutlich, dass sich alle drei Kundenanforderungen unterscheiden – was durchaus üblich ist. Das Produkt (P) wird nun so positioniert, damit alle Kunden irgendwie damit zurechtkommen. Der Kunde erhält nicht unbedingt das, was er/sie benötigt.
Die Logik dahinter ist immer noch zu oft der Break.Even-Gedanke. Das heißt, es müssen genügend viele Produkte einer Art hergestellt werden, damit es sich für das Unternehmen rechnet. Diese Skalierung (Menge) führt dann zu akzeptablen Preisen – so die altbekannte Logik.
In diesen „akzeptablen Preisen“ sind allerdings auch die Kosten der Überproduktion (mehrere hundert Milliarden Euro pro Jahr) enthalten, deren Vernichtung der Kunde mit dem Preis der Ware auch bezahlt. – von den Retouren ganz zu schweigen.
Seit Jahrzehnten ist es möglich, massenhaft Bekleidung herzustellen, die individuell ist, und zum Preis einer in großen Mengen hergestellten Massenware zu erhalten ist.
Es stellt sich natürlich die Frage: Warum wird das nicht genutzt?
In der Zwischenzeit verfestigt sich bei mir die Auffassung, dass die Kunden nicht das physische Produkt, sondern hauptsächlich die aufgeladene Marke (Werbe-Ikonen, Influencer, Marketing, In-Out, usw.) kaufen – egal ob das Bekleidungsstück passt oder nicht. Wenn nicht, wird es angepasst – Änderungsschneidereien in 1a-Lagen haben Hochkonjunktur. Wie in der Abbildung mit dem Kreis dargestellt, umfasst – ja überstrahlt – die Marke alle Kundenanforderungen.
Bei einem individuell hergestellten Bekleidungsstück (mass customized) würde es ein Produkt sein, dass passt, preislich OK ist, doch möglicherweise nicht dem vorgegeben modischen Trends entspricht. Auch die Marke würde fehlen – und wer will das schon? Immerhin dient das Kleidungsstück ja auch zu einem großen Teil der Kommunikation. Kleider machen eben Leute.
Wenn Sie sich zu diesen und anderen Themen informieren wollen: Die MCP Community of Europe trifft sich auf der Konferenz zu Mass Customization and Personalization – MCP 2026 – vom 16.-19.09.2026 in Balatonfüred, Ungarn. Wir sind dabei.
Die verwendete Sprache, und hier speziell die verwendeten Begriffe, lassen oft Rückschlusse auf die dazugehörende Denkweise (Mindset) zu. Beispielsweise ist die Metapher „Unternehmen als Maschine“ oder „Menschen sind Zahnräder“ sinnbildlich für eine sehr mechanistische Denkweise, die heute in vielen Bereichen nicht mehr angemessen erscheint.
Der Begriff „Verbraucher“ hat eine ähnliche Wirkung. In vielen Meldungen, Statistiken usw. wird immer noch der Begriff verwendet, gerade so, als ob alle Produkte und Dienstleistungen verzehrt werden, also einer Abnutzung unterliegen.
„Verbrauch ist in der Wirtschaftstheorie der Verzehr von Gütern und Dienstleistungen zur direkten oder indirekten Bedürfnisbefriedigung. Ein Synonym für Verbrauch ist Konsum“ (Quelle: Wikipedia) Bei einem Acker ist das so, da hier die Fläche begrenzt, und nicht so einfach erweiterbar ist. Es leuchtet daher ein, dass versucht wird, das „maximale aus dem Boden herauszuholen“.
Bei digitalen Produkten ist das etwas anders. Auf das eben beschriebene Beispiel angewendet bedeutet das: „Der digitale Acker ist ein Zauberhut, aus dem sich ein Kaninchen nach dem anderen ziehen lässt, ohne dass er jemals leer würde. Die »Verbraucher« von Informationsgütern »verbrauchen« ja eben gerade nichts“ (Grassmuck 2004, Bundeszentrale für politische Bildung (bpb), 2., korrigierte Auflage).
In einer immer stärker digitalisierten Welt, werden digitale Produkte und Dienstleistungen durch deren Nutzung nicht „verbraucht“, sondern ganz im Gegenteil: Durch die Nutzung von Daten und Informationen entstehen wieder viele neue Daten, die dann oftmals von Unternehmen wertschöpfend genutzt werden. Daten sind für diese Unternehmen das neue Öl.
Im Zusammenhang mit digitalen Produkten (Daten, Informationen, Wissen) sollten wir daher nicht mehr von „Verbraucher“ sprechen, da der Begriff einfach nicht mehr passt.
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche, psychologische oder berufliche Themen zu analysieren. Der Ratgeber ist in diesen Fällen also nicht der Arzt, der Psychologe, oder ein Kollege am Arbeitsplatz, sondern ChatGPT oder andere bekannte KI-Modelle.
Es ist in dem Zusammenhang wichtig, welche Werte von dem KI-Modell „vertreten“ werden. Warum? In dem Beitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich, wie unterschiedlich die Werte von KI-Modellen der US-amerikanischen Tech-Konzerne, chinesischen Modellen, und europäischen Modellen sein können.
Da wiederum Werte Ordner sozialer Komplexität sind, ermöglichen sie ein Handeln unter Unsicherheit und bestimmen die menschliche Selbstorganisation.
Systemische Sicht auf Werte: „Werte können als Ordnungsparameter (Ordner) selbstorganisierter komplexer biotischer, individueller, gruppenförmiger oder aggregierterer sozialhistorischer Systeme aufgefasst werden. Diese Ordner bestimmen oder beeinflussen zumindest stark die individuell-psychische und sozial-kooperativ kommunikative menschliche Selbstorganisation und ermöglichen eben damit jenes Handeln unter prinzipieller kognitiver Unsicherheit“ (Haken 1996).
Die nächste internationale Konferenz MCP 2026 zu Customization and Personalization findet vom 16.-19.09.2026 in Balatonfüred, Ungarn statt. Die MCP Community of Europe trifft sich zum Austausch der verschiedenen Perspektiven auf das Thema. Seit 2004 ist das die 12. Konferenz, die durchgehend alle 2 Jahre durchgeführt wird.
12th International Conference on Customization and Personalization
7th Doctoral Students Workshop
4th Professionals Panels & MEA KULMA Innovation Festival
Conference Abstract Submission Deadline: March 31, 2026.
Sprechen Sie mich gerne an, wenn Sie Fragen zur Konferenz haben. Wir werden auch dabei sein.
In früheren Beiträgen hatte ich schon darauf hingewiesen, dass der Großteil der Trainingsdaten der bekannten KI-Modelle aus englischsprachigen (chinesischen) Elementen zusammengesetzt sind. Das Open Source AI-Modell für Europa Teuken 7B hat hier angesetzt, und enthält daher mehr als 50% non englisch data.
Es stellt sich dabei natürlich auch die Frage, warum es so wichtig ist, Trainingsdaten in den jeweiligen (europäischen) Sprachen zu haben. Dazu habe ich eine Erläuterung zur ungarischen, bzw. finnischen Sprache gefunden:
„The current landscape is dominated by models pretrained on vast corpora composed predominantly of English and a few other high-resource languages, creating a significant performance and resource disparity for less-resourced linguistic communities (Zhong et al. 2025). For medium-resource languages such as Hungarian, a Finno-Ugric language characterized by its agglutinative nature and rich morphology, this gap is particularly pronounced. Off-the-shelf multilingual models often exhibit suboptimal performance due to insufficient representation in training data and tokenizers that are ill-suited to language specific morphology. This is particularly the case for open-source models, which visibly struggle with Hungarian grammar“ (Cesibi et al. 2026).
Die hier angesprochenen Agglutinierenden Sprachen (Wikipedia) sind gar nicht so selten. Neben der hier angesprochenen ungarischen Sprache, sind das auch Finnisch, Baskisch, Japanisch, Türkisch usw. Schauen Sie sich dazu bitte die angegebene Wikipedia-Seite an, Sie werden überrascht sein.
Für all diese Sprachen macht es also Sinn, spezifische Trainingsdaten in der jeweiligen Sprache, inkl. der jeweiligen Besonderheiten zu entwickeln. In der Zwischenzeit ist dieser Trend auch deutlich zu beobachten, nicht nur bei den Agglutinierenden Sprachen.
Diese speziellen KI-Modelle können gerade für kultur-, sprachen- und kontextbezogene Innovationen geeignet sein. Siehe dazu auch
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche oder psychologische Themen zu analysieren. Der Ratgeber ist dann also nicht der Arzt oder der Psychologe, sondern ChatGPT oder andere bekannte KI-Modelle.
Bei der Kommunikation Mensch – KI dringt die KI immer tiefer in das Profil des Menschen ein. Die Profile werden dann auch dazu genutzt, dem Nutzer zu schmeicheln.
Schmeicheln bedeutet „jemandem übertrieben und nicht ganz aufrichtig Angenehmes sagen, um dessen Gunst zu gewinnen“ (Quelle).
In einer Studie (Jain et al. 2026) wurden zwei Schmeicheleien unterschieden: (1) Zustimmungsschmeichelei (agreement sycophancy) – die Tendenz von Modellen, übermäßig positive Reaktionen hervorzurufen, und (2) Perspektivenschmeichelei (perspective sycophancy) – das Ausmaß, in dem Modelle die Sichtweise eines Nutzers widerspiegeln.
Es stellte sich daher die Frage: Verstärkt Personalisierung das Ausmaß der Schmeicheleien?
„Our results raise the question of whether some personalization approaches may amplify sycophancy. Prior work often attributes sycophancy to preference alignment, since users prefer responses that are affirmative or aligned with their perspective. Yet in aligned models, we find that user memory profiles are associated with further increases in agreement sycophancy, and that contexts providing more information about the user drive perspective sycophancy“ Source: Jain et al. (2026): Interaction Context Often Increases Sycophancy in LLM | PDF
Es wurde also in der Studie klar, dass Nutzerprofile eher Zustimmungsschmeicheleien, und Kontextinformationen eher Perspektivenschmeichelei verstärken. Egal welches Element man also betrachtet, Schmeicheleien verstärken sich wohl mit der Zeit.
Bei diesen Entwicklungen stehen wir noch am Anfang, doch deutet sich schon jetzt ein entsprechender Klärungsbedarf an: Wie können Personalisierung und Schmeicheleien ausbalanciert werden? Siehe dazu auch
Auf den verschiedenen Konferenzen, an denen ich teilgenommen habe, ging es über viele Jahre um Mass Customization and Personalization. Auslöser der Entwicklung war die Veröffentlichung B. Joseph Pine II (1992): Mass Customization. The New Frontier in Business Competition, in der die damals neue hybride Wettbewerbsstrategie vorgestellt wurde.
In der Zwischenzeit gibt es beim Fraunhofer Institut in Stuttgart das Leistungszentrum Mass Personalization. Dort ist man der Auffassung, dass es sich bei Mass Personalization um einen Megatrend handelt
„Mass Personalization ist ein eigenständiges radikal nutzerzentriertes und dennoch nachhaltiges und ressourceneffizientes Konzept, das als Toolbox oder plattformtechnologische Anwendung in der Produktion von morgen fungieren kann“ (Krieg/Groß/Bauernhansl (2024) (Hrsg.): Einstieg in die Mass Personalization. Perspektiven für Entscheider).
Mass Customization ist hier zeitpunktbezogen, und Mass Personalization eher Zeitdauer bezogen zu interpretieren. Beides, Mass Customization und Mass Personalization, sind allerdings immer noch aus der Perspektive des Unternehmens gedacht.
Wenn sich ein Unternehmen auf jeden einzelnen Nutzer so intensiv einstellen will, benötigt es viele Problem- und möglicherweise auch erste Lösungsinformationen vom Nutzer. Bei komplexen Problemen sind diese Informationen nur sehr schwer zu beschreiben (Kontext, Implizites Wissen, Expertise), und schwer vom Nutzer zum Unternehmen übertragbar (Sticky Information, Träges Wissen).
Der Nutzer weiß oft am besten, was er für sein Problem benötigt. Es fehlt oft noch der Schritt zur ersten Umsetzung von eigenen Lösungen. Dieser war in der Vergangenheit sehr aufwendig (Zeit, Geld), sodass die Umsetzung oft von Unternehmen übernommen wurde.
In der Zwischenzeit gibt es durch die Möglichkeiten der Künstlichen Intelligenz, des 3D-Drucks (Additive Manufacturing), oder auch der Robotik und der Open Source Community viele Möglichkeiten, das Produkt selbst zu entwickeln und im Idealfall selbst oder in einer Community herzustellen. Siehe Eric von Hippel (2016): Free Innovation (Open Access).
Titel (Ausschnitt) https://direct.mit.edu/books/book/5344/Free-Innovation
Eric von Hippel hat dazu schon sehr viele Studien veröffentlich, aus denen hervorgeht, dass der Anteil dieser Open User Innovation in den letzten Jahrzehnten stark angewachsen ist. Diese Innovationen findet man nicht in den offiziellen Statistiken zu Innovationen, denn Innovationen werden dort von Unternehmen entwickelt und auf den Markt gebracht. Was versteht nun von Hippel unter Open User Innovation?
„An innovation is ´open´ in our terminology when all information related to the innovation is a public good—nonrivalrous and nonexcludable”(Baldwin and von Hippel 2011:1400).
”… involves contributors who share the work of generating a design and also reveal the outputs from their individual and collective design efforts openly for anyone to use“ (Baldwin and von Hippel 2011:1403).
Wir wissen alle, dass die Unternehmen nur die Innovationen auf den Markt bringen, die eine entsprechende Rendite versprechen – alles andere bleibt liegen… Doch genau darin liegt die Chance von Open User Innovation: Jeder einzelne kann nicht nur kreativ, sondern auch innovativ sein (Ideen umsetzen) und seine Innovationen anderen (auch kostenlos) zur Verfügung stellen.
Sie meinen das gibt es nicht? Dann schauen Sie sich einmal die vielen Plattformen zu Open Source Software, oder die Plattform Patient Innovation an – Sie werden staunen.
Wenn Sie sich zu diesen Themen informieren wollen: Die MCP Community of Europe trifft sich auf der Konferenz zu Mass Customization and Personalization – MCP 2026 – vom 16.-19.09.2026 in Balatonfüred, Ungarn. Wir sind dabei.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.